Fifty-five percent of technology and security executives in our Global DTI 2021 survey plan to increase their cybersecurity budgets, with 51% adding full-time cyber staff in 2021 — even as most (64%) executives expect business revenues to decline. Clearly, cybersecurity is more business-critical than ever before.
That’s why cyber resilience is so critical for organizations today.
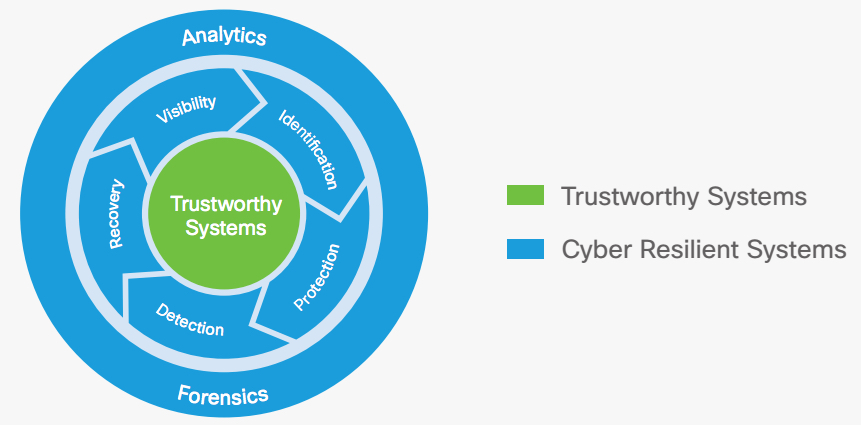
Cisco, defines cyber resilience as the ability to prepare for and adapt to changing threat conditions while withstanding and rapidly recovering from attacks to infrastructure availability. It is largely about managing risk – identifying events that might happen; assessing how likely they are to happen and the impact they could make; and deciding what actions to take.
Key capabilities include:
Identification. First, you need to identify your most valuable assets, so you can make informed decisions about risk and investment. It’s also necessary to perform an asset management and risk assessment. To achieve this, it’s essential to be able to know and authenticate all systems in your network architecture, so one party can confidently identify another party. You must know which devices – with specific cyber resilient capabilities – form the foundation of your cyber resilience and business competencies. You must also know where your business-critical data is and understand its resiliencies. Only then can you develop and maintain a security strategy.
Protection. The next step is to limit or contain the impact of attacks. Policies, processes and mechanisms ensure that systems are built and operate in a state of integrity during an attack, and that they are defended from modification from unauthorized or unauthenticated processes.
Detection. Security teams must constantly measure, collect, verify and analyse system integrity to enable timely discovery of a threat. Detection solutions provide behaviour notifications, logging and forwarding events related to unexpected and possibly harmful user behaviour or network activity.
Recovery. Recovery restores the normal operation of platforms, apps and services if they are corrupted by a compromise. New platform capabilities, for example, will allow an agent to run and correct or replace compromised components, including firmware, applications, user data, configuration data and software. This greatly reduces costs and downtime when an attack occurs.
Visibility. With visibility mechanisms supporting protection, detection, recovery, analytics and forensics, you assure continuous awareness of system integrity. Visibility tools are typically integrated with other cyber resiliency functions to establish a coordinated security and compliance posture that can reveal the state of system integrity to administrators, users, tools, applications or third parties.
Analytics. Through analytics, you examine incident data to augment situational awareness, helping security teams distinguish events that pose the greatest risk. In addition, these tools reduce the time from detection to recovery, paving the way for the proactive defence of your network.
Forensics. Teams ingest relevant support data, while preserving, processing, analysing and presenting system-related evidence in support of recovery.
These capabilities will not entirely eliminate cyber risk; but they create awareness to the risks and will build a formidable defensive posture to significantly reduce the impact of threats.
Quality NOC could be your Resilience Partner. Contact us
Reference: https://blogs.cisco.com/security/why-the-seven-steps-of-cyber-resilience-prove-critical-for-digital-transformation